

Building SBOMs for COTS Android Apps
Abstract
Deepbits developed a new technique that can detect third-party libraries and their versions accurately and efficiently. Detecting third-party libraries in Android apps is an important prerequisite for SBOM generation and management. However, transitive dependencies, partial builds, and code obfuscation make detecting third-party libraries difficult, let alone pinpointing the exact versions. For years, people tried different approaches and feature engineering to be lenient and tolerant but also precise and accurate at the same time, but failed. Deepbits solved this problem using a powerful NLP model. Evaluations show it outperforms the existing approaches in detecting third-party libraries and versions, with or without code obfuscation.
The problem
Third-party libraries are widely used in Android applications to reduce developers' efforts and bring better modularization. To better manage the third-party libraries and dependencies used in the codebase, the idea of “software bill of materials” (SBOM) is proposed. An SBOM is more than just a list of components in the codebase. It also contains versions, license information, patch status, etc., to allow security teams quickly locate issues or risks, and to help evaluate the quality of a program.
For Android apps, SBOMs not only help governments and companies to check regulation violations but also help individual users to evaluate the trustfulness of an app. SBOMs are supposed to be provided by developers or vendors. However, most of them are reluctant to do so. What’s worse, even if they want to, it is not a trivial task due to transitive dependencies.
To solve this problem, many third-party library detection approaches have been proposed. However, they all have their limitations. The library code is transformed a lot during integration into the host app. Functions and classes can be potentially removed (dead code elimination), class names and variable names can be shortened (to save space), functions can be inlined, package layout can be flattened, and control flow can be obfuscated. Due to the transformations, the existing approaches manually crafted some features that survive the transformations, such as strings, call graphs, normalized instructions, etc. Even so, they are still struggling halfway toward precise detection, especially when facing obfuscations.
Our solution
Deepbits developed a new approach that can automatically extract high-quality features and detect third-party libraries at very high precision and recall. Other approaches have low precision and recall (see the result table below) because they use manually crafted features, which are either unstable or not differentiable enough due to the vast code transformations during the build.
Android third-party library detection comes down to function matching. Because of dead code elimination, partial build, and function inlining, matching a whole library in the host app is unlikely. That is why we need more fine-grained matching, and in our case, it is function matching. To find equivalent function pairs, we leverage the powerful NLP model, BERT, to measure similarities between functions. This similarity mechanism allows us to find function pairs that are not exactly equivalent, syntactically or semantically, due to minor patches, code obfuscation, etc. To train the BERT model for similarity measurement, we first pre-train the model on the source code of Android apps so that the model captures the linguistic features of Android functions. Then, we finetune the model by feeding positive and negative function pairs to guide the model to focus more on function logic, control flows, and features that are relatively stable under obfuscation while paying less attention to user-defined strings such as variable names and function names that can be easily obfuscated. A positive function pair consists of equivalent functions. In our case, we first collect decompiled functions from Android apks (including the ones protected by obfuscator), and we consider decompiled functions equivalent if they were previously compiled from the same source code. In this way, the model learns how obfuscation changes functions, and what features should be picked up to achieve a better result. Similarly, negative pairs are constructed by randomly selecting decompiled functions that were compiled from different source code so the model can figure out how to differentiate functions. In this way, we let the NLP model figure out the features it should extract, weight parameters, etc., and the features it learns are more complete and general than manually crafted features, as we can see in our evaluation below.
Results
To evaluate the performance of our approach, we collect Android apks from GitHub - presto-osu/orlis-orcis: Orlis/Orcis , a public dataset containing over 870 third-party libraries and about 200 host apps. The public dataset also contains obfuscated apps by three obfuscators: Allatori, dasho, and ProGuard. Similar to R8, ProGuard is an Android tool aiming to reduce APK size, so it mainly removes dead code and renames variable, function, and class names, but it doesn’t do much in terms of obfuscation. Allatori and dasho do more than code shrinking. They also make reverse engineering difficult by introducing more obfuscations such as control flow flattening, string encryption, and debug info obfuscation. Since our model is only trained to understand the code obfuscated by dasho, the evaluation on Allatori can give us an insight into the generalizability of our approach. We use two academic approaches, LibID and LibPecker, as our baselines.
As shown in Figure 1 and Figure 2, our approach has better accuracy of third-party library detection when the host apps are obfuscated. Our version matching result also confirms that our approach outperforms the baselines.
If you are interested, try our online SBOM tool here.
Library Matching
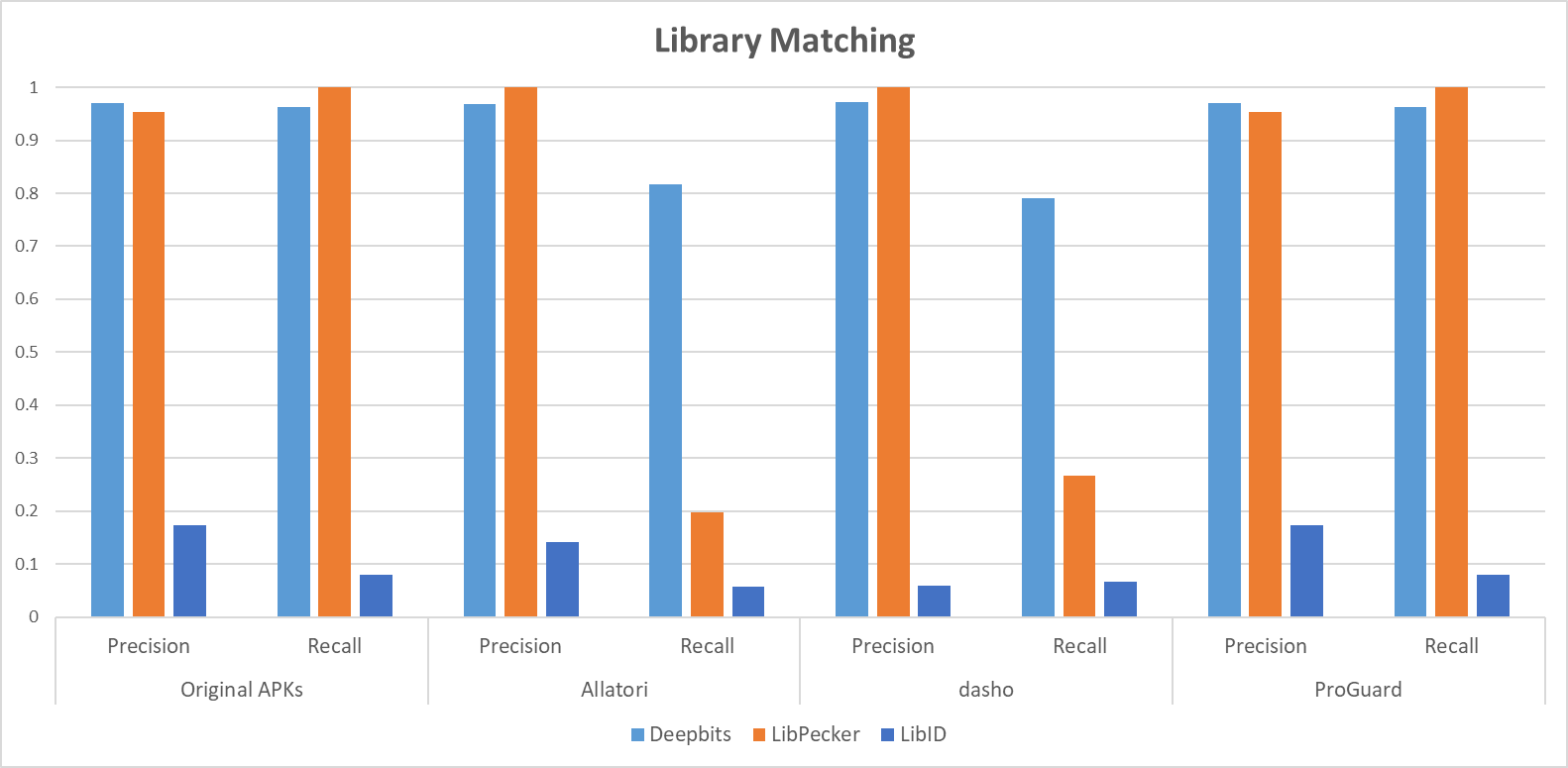 Figure 1. Precision and recall when matching 3rd-party libraries in different datasets
Figure 1. Precision and recall when matching 3rd-party libraries in different datasets
Version Matching
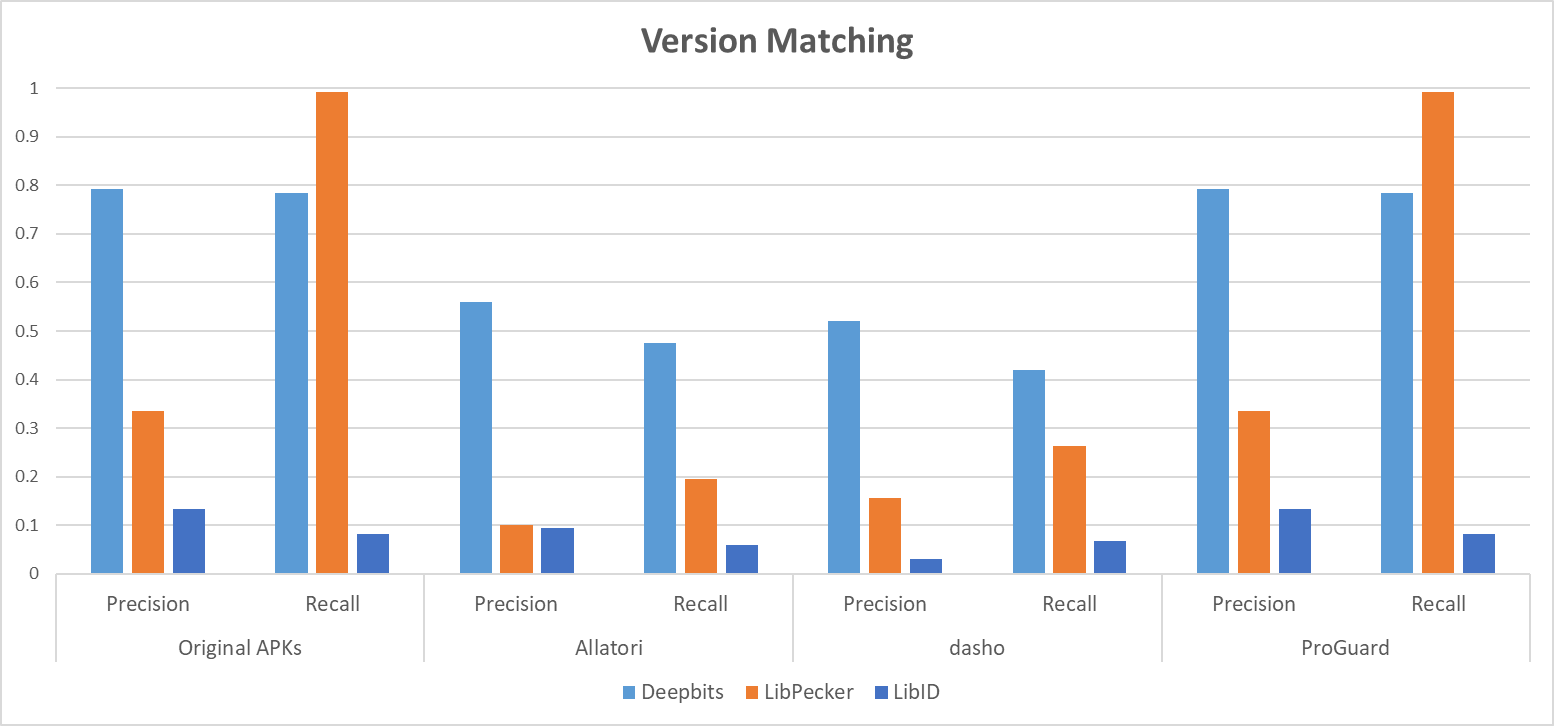 Figure 2. Precision and recall when matching 3rd-party libraries and their versions in different datasets
Figure 2. Precision and recall when matching 3rd-party libraries and their versions in different datasets